
Metadata
- Author: learnpytorch.io
- Full Title: 01. PyTorch Workflow Fundamentals
- Category:articles
- Summary: The text covers a standard PyTorch workflow for building and training models, including creating linear regression models and making predictions. It emphasizes the importance of subclassing nn.Module for creating neural network models in PyTorch. Additionally, it discusses key steps like setting up loss functions, optimizers, training loops, and saving/loading models for inference.
- URL: https://www.learnpytorch.io/01_pytorch_workflow/
Highlights
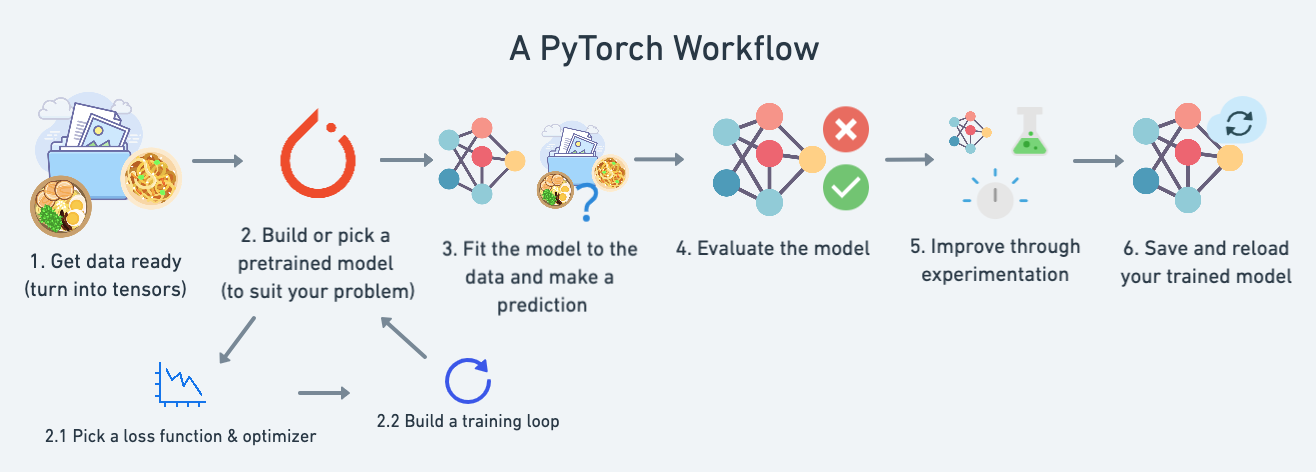 (View Highlight)
(View Highlight)- the above is a good default order but you may see slightly different orders. Some rules of thumb:
• Calculate the loss (
loss = ...) before performing backpropagation on it (loss.backward()). • Zero gradients (optimizer.zero_grad()) before stepping them (optimizer.step()). • Step the optimizer (optimizer.step()) after performing backpropagation on the loss (loss.backward()). (View Highlight) - Why call
torch.load()insidetorch.nn.Module.load_state_dict()? Because we only saved the model’sstate_dict()which is a dictionary of learned parameters and not the entire model, we first have to load thestate_dict()withtorch.load()and then pass thatstate_dict()to a new instance of our model (which is a subclass ofnn.Module). Why not save the entire model? Saving the entire model rather than just thestate_dict()is more intuitive, however, to quote the PyTorch documentation (italics mine):The disadvantage of this approach (saving the whole model) is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved…
Because of this, your code can break in various ways when used in other projects or after refactors. So instead, we’re using the flexible method of saving and loading just the
state_dict(), which again is basically a dictionary of model parameters. (View Highlight) - Why call
torch.load()insidetorch.nn.Module.load_state_dict()? Because we only saved the model’sstate_dict()which is a dictionary of learned parameters and not the entire model, we first have to load thestate_dict()withtorch.load()and then pass thatstate_dict()to a new instance of our model (which is a subclass ofnn.Module). Why not save the entire model? Saving the entire model rather than just thestate_dict()is more intuitive, however, to quote the PyTorch documentation (italics mine):The disadvantage of this approach (saving the whole model) is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved…
Because of this, your code can break in various ways when used in other projects or after refactors. So instead, we’re using the flexible method of saving and loading just the
state_dict(), which again is basically a dictionary of model parameters. (View Highlight) - Why not save the entire model? (View Highlight)
- Note: The disadvantage of this approach (saving the whole model) is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved… Because of this, your code can break in various ways when used in other projects or after refactors.
- The disadvantage of this approach (saving the whole model) is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved… Because of this, your code can break in various ways when used in other projects or after refactors. (View Highlight)